Can AI Business Models Be Profitable? Yes.
Exploring the cost of running LLMs and whether AI start-ups can achieve everyone's favourite SaaS gross profit margins.

The cost of running a Large Language Model (LLM) is a source of constant discussion in the start-up ecosystem. The fear in the hearts of VCs and Founders alike is that the sexy new AI platform you are building is inescapably cursed with structural negative gross profit margins. The battle is whether the price you can charge for your service is more than the cost to run the model providing the service (I promise the thinking in this article gets deeper).
Goldman Sachs has certainly turned against AI lately, effectively framing the entire industry as a Ponzi scheme centred around selling NVIDIA GPUs. This is because spending vastly outpaces productive output. One of the big barriers to building useful AI apps has been the debilitating cost vs quality trade-off. This has meant that even if you can design a mind-blowing AI solution, the first barrier to implementation is whether it is economically feasible.
Now is a perfect time to explore this cost conundrum as OpenAI has released GPT-4o Mini, their most cost-efficient model to date. What does this mean for start-ups? Is your AI side hustle finally profitable? Can LLMs now efficiently solve all my problems?
Let’s explore these questions by seeking to understand whether Perplexity, the leading AI-powered search engine, can be profitable (a little hint: it certainly can be).
🪙 First, why does using an LLM cost money?
Tokens. Tokens. Tokens. If you are not a degenerate, the last time you used tokens as currency was back in the days before Timezone moved to card payments. For the rest of us who tried to make a buck in web3, the last tokens we used were non-fungible images of monkeys.
In the world of LLMs, tokens return in a big way, representing the cost of generating a small chunk of characters. A token can represent words, subwords, or single characters. Tokens are the building blocks of LLMs, which (in their simplest form) can be thought of as machines predicting the next token based on a chain of input tokens (the “context window”). The average word contains four tokens.

Perfect LLM token prediction in action.
The processing time required to generate the next token scales with the number of tokens in the context window. As you can imagine every time a new token is generated it is added to the context window used for generating the next token. This means the cost of generating aggressively scales with the number of tokens you want to generate (this is why output tokens cost more than input tokens).
“Time is Money” - Benjamin Franklin
Why does generating a token cost money? Well if we tried to generate a token ourselves using an open-source model we would need two things: a GPU and electricity. These have two associated costs which scale with time, being the depreciating value of the GPU and the amount of electricity we use. Given generating a token on a GPU requires processing time, we can see that each time we generate a token we can attribute a depreciation and electricity cost based on the amount of time taken to generate.
Of course, you don’t want to buy a GPU because you don’t need to run it at full capacity all the time, so the next best thing is to rent GPU processing time from a cloud provider. This allows you to generate your tokens on someone else’s GPU. While there are benefits of scale on the provider side which can bring down costs, you will need to pay a premium for the ease of access.
The final layer of cost is model access, if you want to run one of OpenAI’s models, you have to go through their API and run it on their GPUs. That means they can charge a premium, although because they have massive scale and are intensely optimising, the cost of using a big foundational model’s API is cheaper than cloud GPUs for the average person.
We will soon explore the cost per token for different providers, but before that let’s think about how many tokens Perplexity is using to service search queries so we can use it as an example.
🔍 What is Perplexity?
Perplexity is an AI-based search engine that scans the web to find relevant articles and responds to questions using foundational LLM intelligence plus the article context. I think it is a great example of a simple AI tool that can be used to understand the cost of running LLMs. This is because it has a really clear input (i.e. question and context) and there is a defined output (the response to your question).
The business model is simple: an all-you-can-eat AI buffet. In a buffet business model, there is a fixed cost associated with access (in this case $20 per month) but you have unlimited access to the buffet (in this case running LLMs to answer search queries). The game is simple, for Perplexity to win, you need to use less than $20 of LLM cost per month (ignoring all other costs associated with providing the service). In the same way, a buffet wins if you load up on carbs like a chump and can’t focus enough time on the oysters.
OpenAI’s chatGPT is also a buffet model, but there are so many different ways someone could be using it so it it becomes hard to create a simple cost model

A Token Buffet. Delicious.
💰 How many tokens is Perplexity using?
Tokens are the currency, how many are Perplexity spending? I have tackled this like a graduate might tackle a case study in a consulting interview. That is to say, we have had to make some potentially egregious simplifying assumptions, but the important part is understanding how it all pieces together.
We are not going to think about super complex efficiency gains, instead, let's think of Perplexity in MVP form, as if we were going to build it over the weekend. This way we’ll get a gauge for MVP costs and whether you can build a competitor as a side project. How does this Perplexity work?
You ask it a question. (approx 20 words).
It grabs five relevant articles to use in its response. (approx 1,500 words each)
It adds some prompt engineering to the response to ensure the answer comes back in the right format (approx 200 words)
It feeds all of this into an LLM.
It outputs a response to your question. (200 words)
So that people don’t immediately pitchfork me saying there are low-hanging efficiency gains here, I get it. We could just extract the relevant parts of the articles to reduce words. We could fine-tune our LLM so it outputs in a certain format and bypasses prompt engineering. We are on day one of our start-up can we please just see if it works before we optimise!
Where does that leave us? Based on my calcs, this is around ~31k input tokens and ~1k output tokens.

My Token Calcs.
🖨️ Is Perplexity a money printer or a burning pile of VC cash?
Every LLM costs a different amount, and the way I think about it is big models which are expensive per token but high quality, and smaller models which are cheaper per token but produce worse outputs. The Aussie home-grown website Artificial Analysis does a really good job of laying out the costs and quality so I recommend this as your first stop for any project.
The question is, can Perplexity service your monthly search volume for less than $20? The answer is: unless you are searching more than 100 times per month, our MVP Perplexity will be profitable even when using cost-inefficient models (GPT-4 or Gemini 1.5 Pro). But, if Perplexity were to use the new GPT-4o mini, they could service almost 4,000 search queries per month before the cost outweighed the subscription. That is a lot of AI buffet eating for the user.
Below is a table summarising the cost of servicing search queries using OpenAI’s suite of LLMs. If a number is orange that means the user is winning at the buffet.

Cost of using OpenAI to service Perplexity search queries.
🔮 AI-Cost Nostradamus.
This was fun. But, what does the future hold for token costs? As LLMs become commoditised, builders will trend towards price as their only decision point between LLM providers. This creates a race to the bottom for foundational models to provide the cheapest token cost to keep users on their platform.
Where else have we seen this dynamic play out? Cloud storage. If someone told you today that it would cost $3k per GB of storage on their cloud system you would call them insane, and yet this was the cost of cloud storage in 1995. The cost of cloud computing dropped an order of magnitude every 4.6 years.
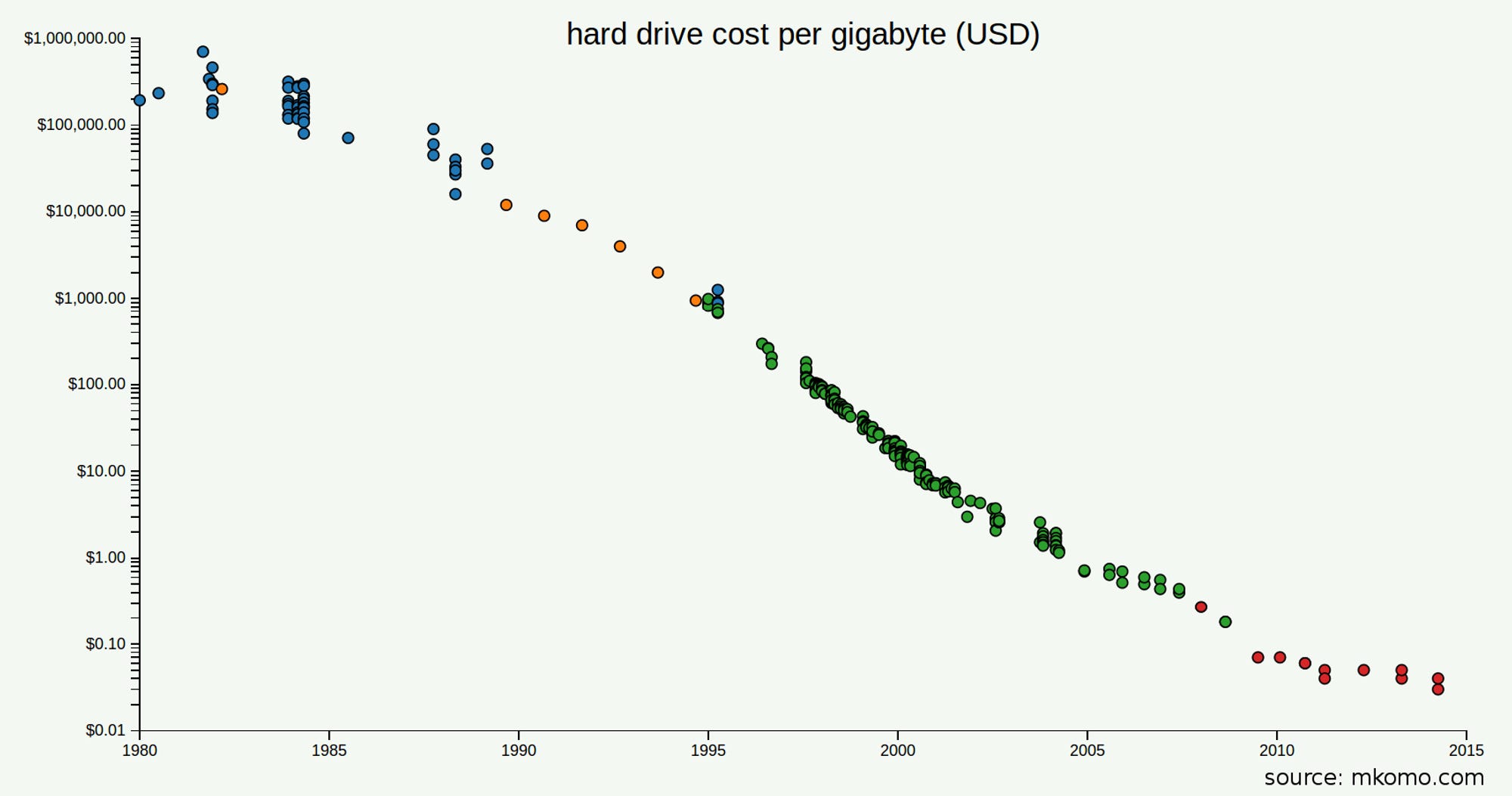
Historic prices of hard drive space, from Matt Komorowski
At the moment some of the gross margins in AI companies might seem slim, but if history tells us anything, capitalising on first mover advantage and capturing customer attention now at a high cost, is going to make you rich when costs drop.
With AI token costs dropping an order of magnitude every six months, your side hustle which seems economically unfeasible now, might soon be the most profitable thing since an NFT drop.
If you want to experiment with costs for yourself using the Perplexity cost model underpinning my calculations, message me on Linkedin or email me at scott@rampersand.com.